Eureka! Teams can now work effectively with large Kotlin and Java classes
1. What's the deal with (large) classes and graphs?
We have dealt with source code in textual format since the advent of assembly and high-level languages in the mid-20th century. We have since then created and modified them with plain text editors to powerful IDEs with syntax highlighting, code completion, and now—integrated AI.
The textual format is our primary way of interacting with source code, which is usually fine. However, things can become hard to grasp when you have source code that does not fit within a few mouse scrolls. That's because we are overwhelmed with information that exceeds human cognitive limits.
We must distill this information meaningfully and fit it inside a single screen to overcome our limitations. Source code is data and behavior put together to solve problems. So, we focus on the members of a class (in object-oriented programming) and the relationships between them. When we do that, we get a directed graph.
2. What's with the visualization?
Graph visualization can be tricky. An edge bundling graph is much better for this use case than other visualizations ( directed graphs, DSMs, etc.). It aims to reduce clutter, reveal high-level patterns, and improve the readability of data. It's particularly useful when dealing with complex graphs that have a large number of nodes and edges. In Eureka, we group fields and methods separately as nodes and draw their relationships. The color of the edge represents the direction of the relationship—red for a dependency and blue for a dependent.
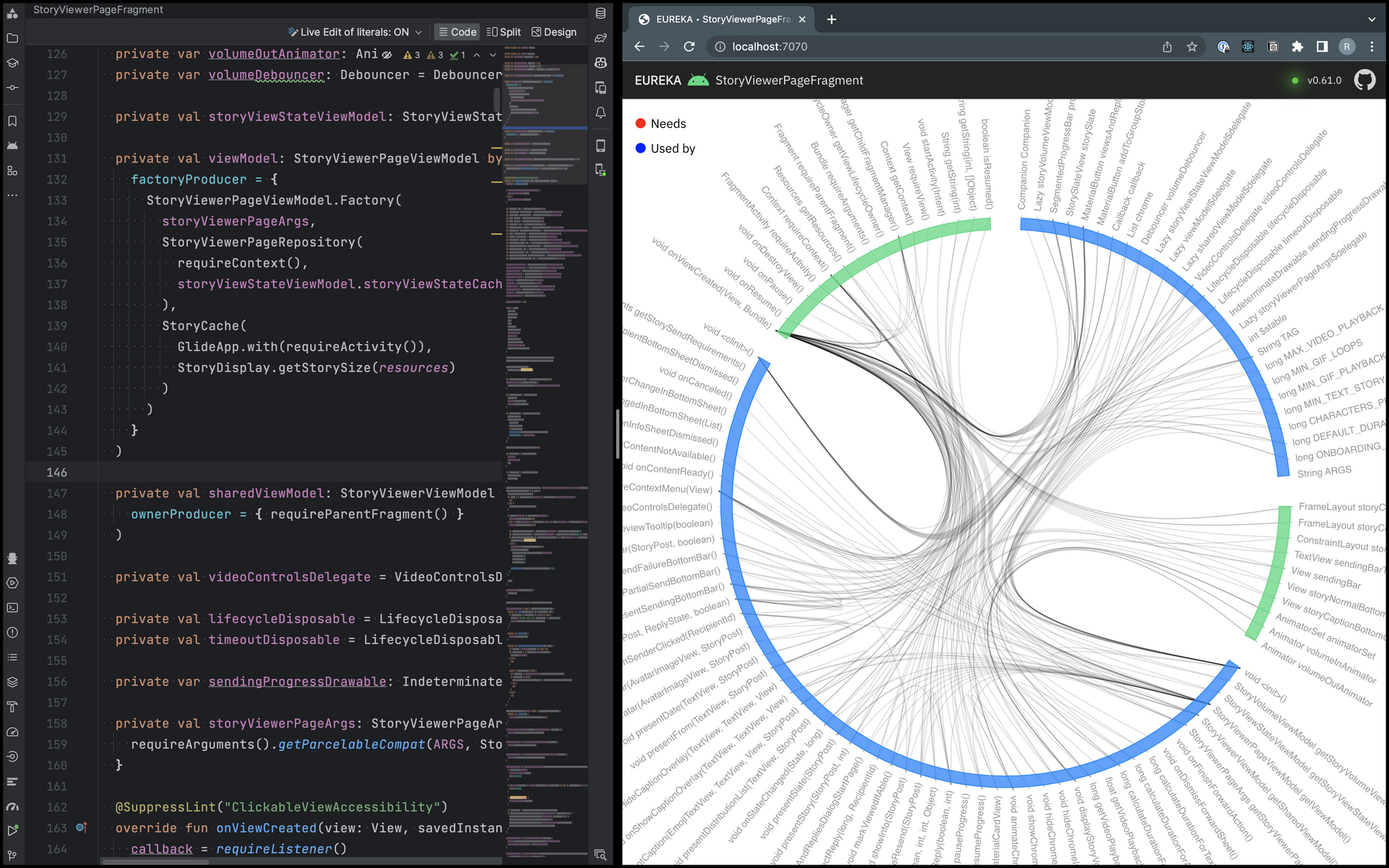
2.1 Why are there four groups?
The groups are color-coded in blue and green. The green groups represent the Android framework's fields and methods. The blue groups are for non-Android fields and methods. Though the graph showcases an Android app's class, the tool works with any Kotlin or Java class.
The graph is interactive, so you can move the mouse pointer over a node to see how it relates to other class members.
3. How to use this information to break down a large class?
Most of the time, when we encounter a large class, we may not know where to start, even if we are familiar with the class. Often we begin addressing various code smells, but to be effective, it helps to tackle the heart of the problem—multiple responsibilities. A class may have become monstrous because it may be doing too many things. It helps to group these responsibilities and create smaller cohesive classes to make it easier to maintain.
One of my favorite insights when tackling legacy code is from Sandi Metz, and it works almost all the time on all large classes. Following is the insight in her own words.
...when we see methods that have a repeating prefix or repeating suffix, there is a tortured object in there that's trying to get out. Right here, in this place, you're about to make a decision that's going to have consequences that echo through your code base forever.
— Sandi Metz (All the little things, RailsConf 2014)
From various codebases, I've understood that it's not just common suffixes and prefixes; even members with common terminologies can form a single cohesive unit that we can encapsulate inside a new smaller class. Eureka has a vocabulary panel that can show you the terminologies in a class, along with a frequency count that you can use to find these members.
4. Exploration
Once you pick a terminology you are interested in, explore the interactive graph by visiting the nodes containing the term. For every incoming and outgoing dependency, write their names on paper. Then traverse the graph and mark each of these nodes as visited. Once you have found a network, stop and prepare for refactoring.
In the following image, the term 'chrome' piqued my interest, and the composite image shows the subgraph with interconnected nodes that fulfill a responsibility. We can extract this subgraph into a class.
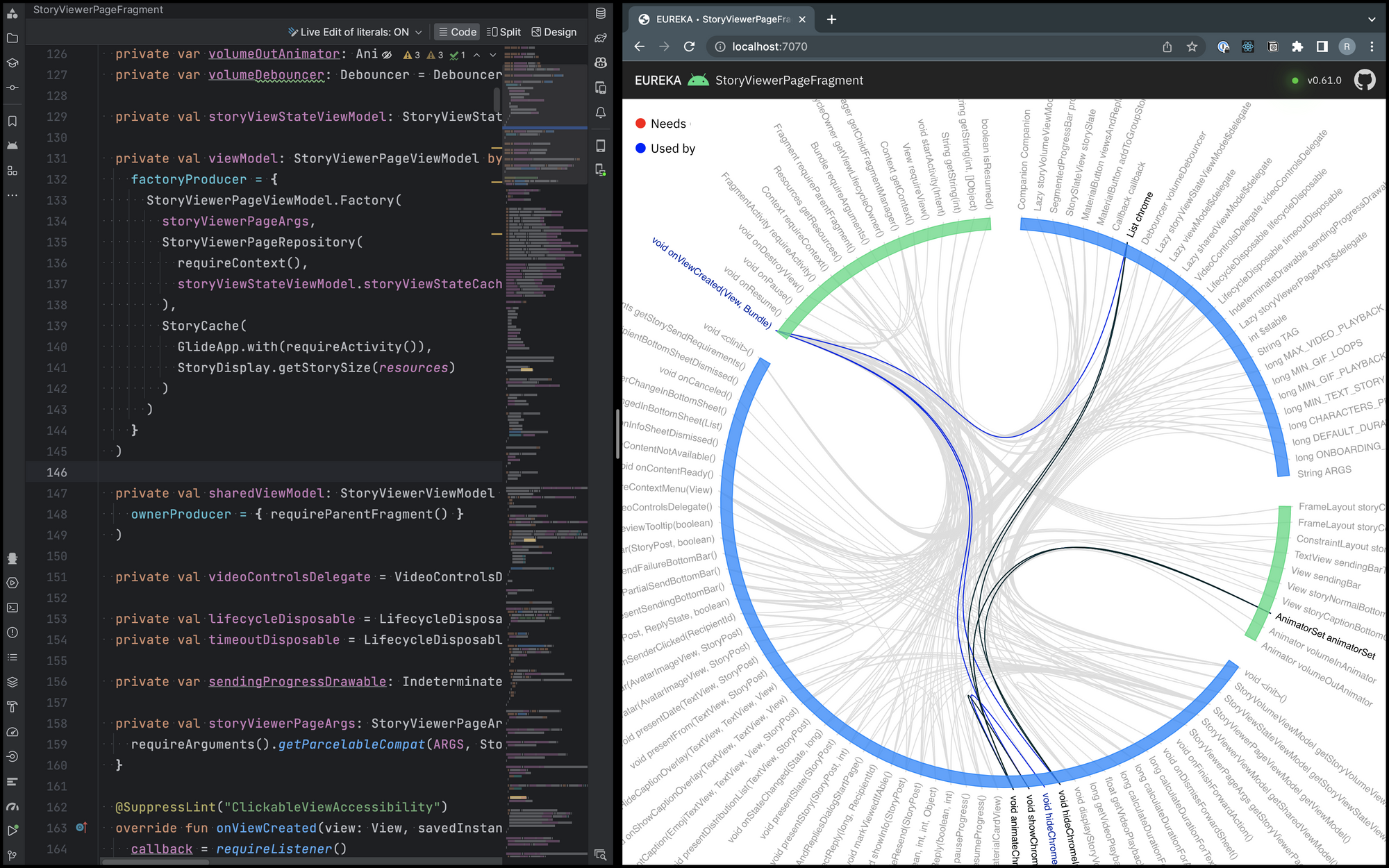
5. Refactoring and extraction
Yes, refactoring needs tests. However, if you only think about traditional automated tests, you may not take advantage of cheaper, faster, and other reliable alternatives. When it comes to refactoring, there are two things we could refactor—behavior and structure. Breaking down a large class is a structural transformation. In languages like Java and Kotlin, with a reliable IDE, you can use the (1) compiler, (2) linter, (3) IDE's refactoring actions, and even (4) git diff to perform provable transformations. These are, in fact, tests for your transformations. Some of the most commonly and frequently used transformations to extract a new class are,
- Introduce parameter
- Introduce functional parameter
- Extract function
- Inline function
- Convert parameter to receiver (Kotlin)
- Move method
- Move field
When done cautiously and with micro-commits, it's possible to refactor and extract a class safely.
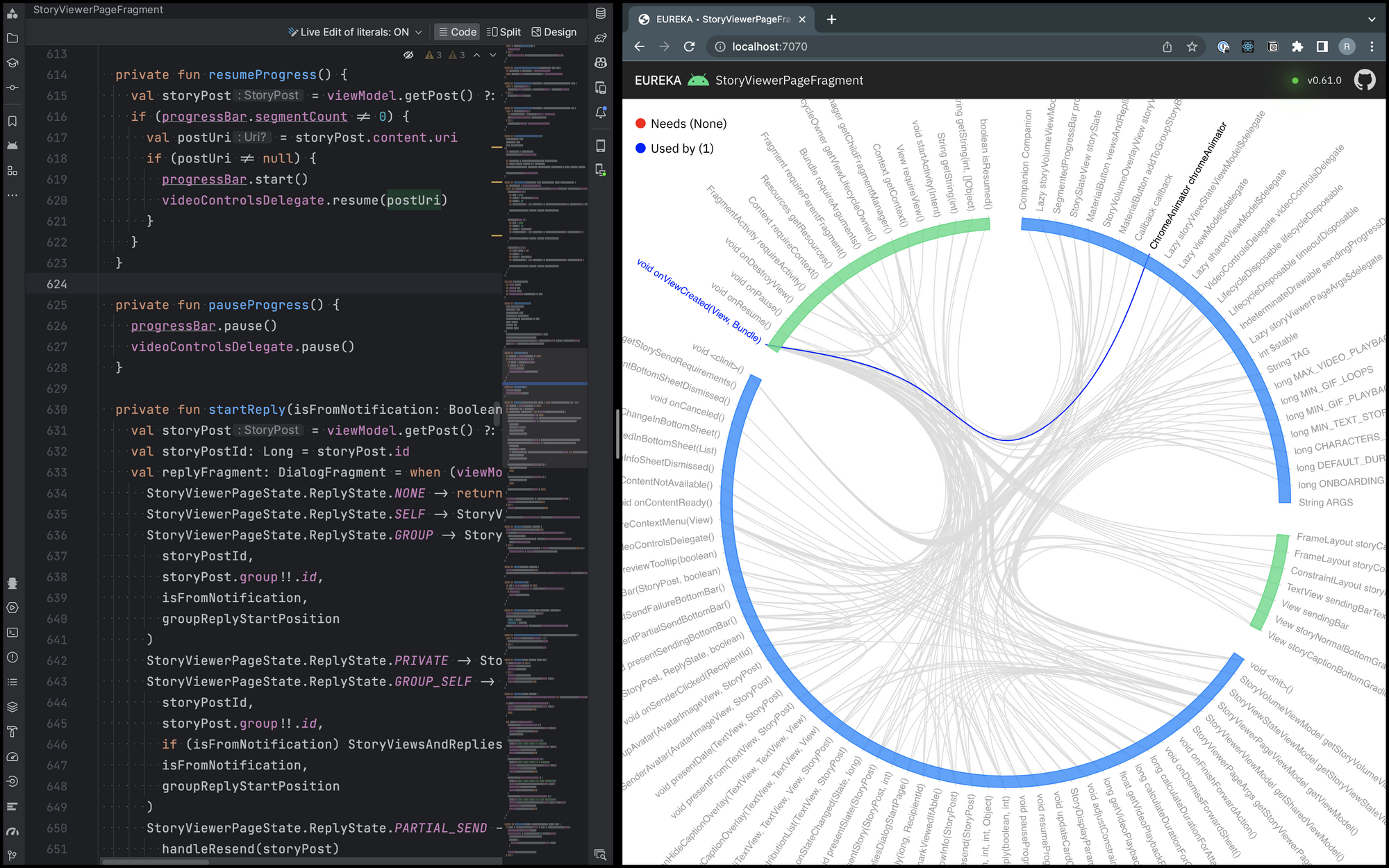
StoryViewerPageFragment after extracting members containing the 'chrome' termThe image above shows the same StoryViewerPageFragment after we extracted all the fields and members containing the
'chrome' terminology. The image showcases a single relationship inside the class, unlike a network of relationships we
had previously.
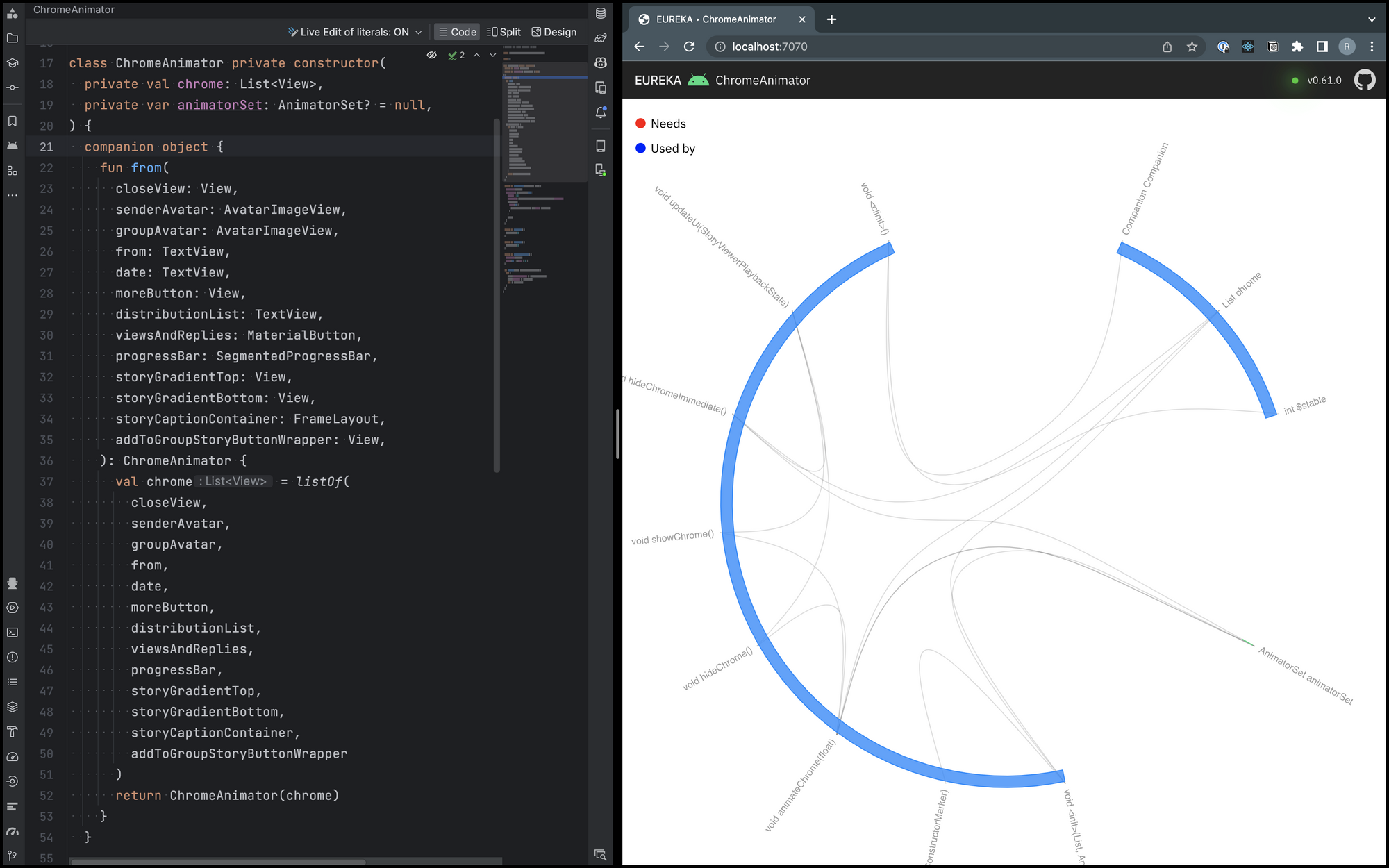
ChromeAnimator classHere's the newly extracted ChromeAnimator class for your reference. The entire network of relationships from
StoryViewerPageFragment lives inside this class now. It only interacts with the fragment through a single public
method.
6. Result
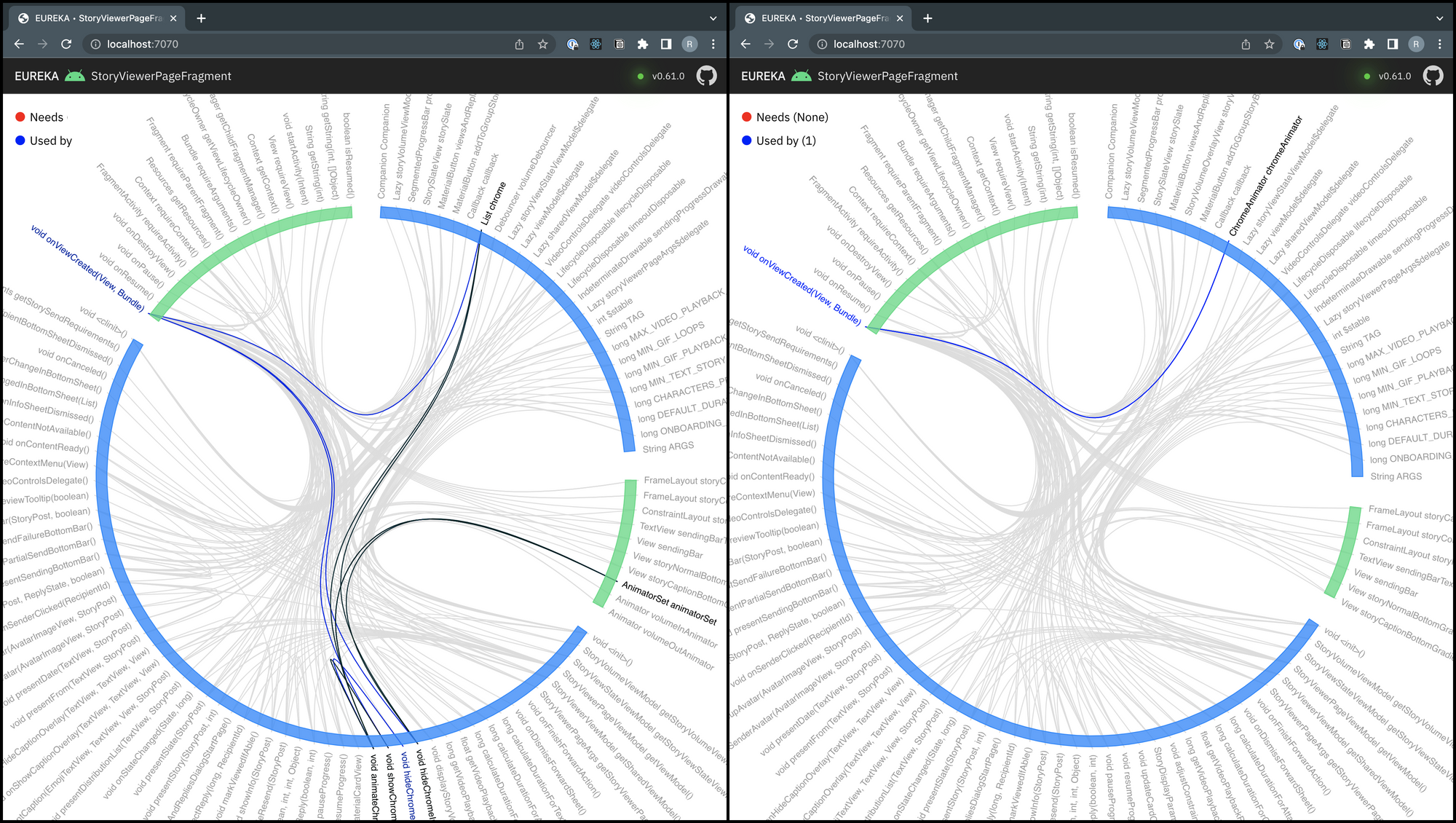
Looking at the structures of the graphs side-by-side, you can notice the amount of cognitive load we have reduced for future maintainers. The number of lines of code is a valuable metric, but in this case, it could not capture the cognitive load the additional lines of code can have on maintainers.
This class is far from being the best version of itself, but you can start looking at the next responsibility to extract away from this humongous class. Smaller classes mean reduced cognitive overhead and improved maintainability.
7. Summary
Large classes are a structural problem. If you want to address a structural problem, we need to see the structure because textual information do not convey this information.
When changing the software structure—using your compiler, linter, IDEs refactoring abilities, or even version control diff as tests is possible.
A visual representation of your code can serve as proof to answer the following questions.
- Did the refactoring effort reduce complexity?
- Does the class have one less responsibility?
- What is the progress on extracting a class, and how much of it is complete?
8. Next steps
If you haven't already, read Refactoring by Martin Fowler and Working Effectively with Legacy Code by Michael Feathers. I'd also recommend Sandi Metz's 99 bottles of OOP.
If you are new to refactoring, there are many useful refactoring katas in several programming languages by Emily Bache. I'd recommend starting with the Gilded Rose kata.
You'd need the tool; you can check Eureka here. It's open source and is
a brew install away.
If your codebase has an unwieldy class that you want me to look into or want to build in-house capabilities for refactoring and dealing with legacy code, reach out to me at [email protected]