
In the traditional sense, writing tests can often be difficult for many developers, especially for code written by someone else. Nevertheless, it's the most reliable way to build and evolve the behavior of our systems.
In a "fast-paced" world of software development, teams find themselves pressured for time. When that happens, many teams
sacrifice testing for adrenaline "speed", making applications less maintainable and sometimes a
minefield for new and existing collaborators.
Imagine being tasked to add or modify behavior in a dense and complex function without tests and documentation. When you can't afford to break any functionality, a task like this becomes daunting and frustrates many developers when done without a safety net.
Gilded Rose: An example
The gilded rose is a famous example that fits the description above. It features a system that updates items in an inventory as they approach their sell-in date. The complexity? Different items on the inventory degrade in quality at different rates. The code is undocumented and has no tests. Relatable much?
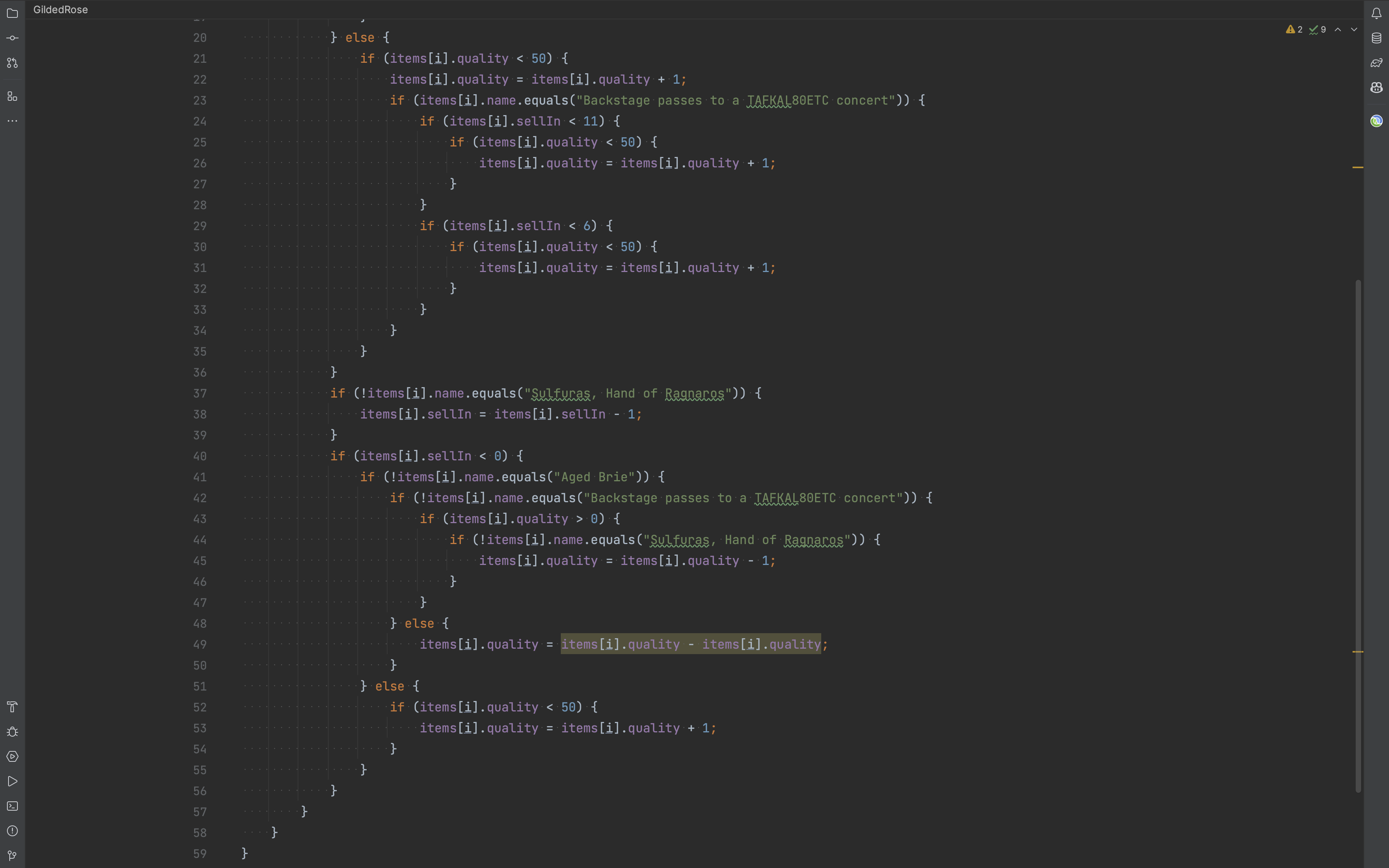
Problems like these frustrate the developers, even the ones with the best intentions. When encountering a situation like this, one could go the traditional route, writing tests one by one to ensure the old behaviors are not affected while adding new ones. However, given the complexity and need for quick results, one could use a different approach.
What tests to write?
When aiming for regression protection, there are only two things.
- Control
- Sensing
1. Control
The core idea behind "control" in testing is to exercise different code paths by changing the inputs. In essence, it's about manipulating the variables or conditions to trigger different execution paths in the program or system.
2. Sensing
Once you control the different execution paths via varied inputs, you need a mechanism to observe or "sense" the outcomes. Sensing is detecting and capturing the effects or changes produced by a function or a piece of code for the given inputs.
Let's say, you have a function that takes an Item as an argument,
public class Item {
public String name;
public int sellIn;
public int quality;
public Item(String name, int sellIn, int quality) {
this.name = name;
this.sellIn = sellIn;
this.quality = quality;
}
@Override
public boolean equals(Object o) {
// … hidden for brevity
}
@Override
public int hashCode() {
// … hidden for brevity
}
@Override
public String toString() {
// … hidden for brevity
}
}
Item class, with name, sellIn, and quality fieldsProviding various values for name, sellIn, and quality will help us control the execution paths within the
function. We can then examine the output to sense the function's effect for each input.
Each combination of these values is a candidate for a test. We can find all potential values for each field from the production code.
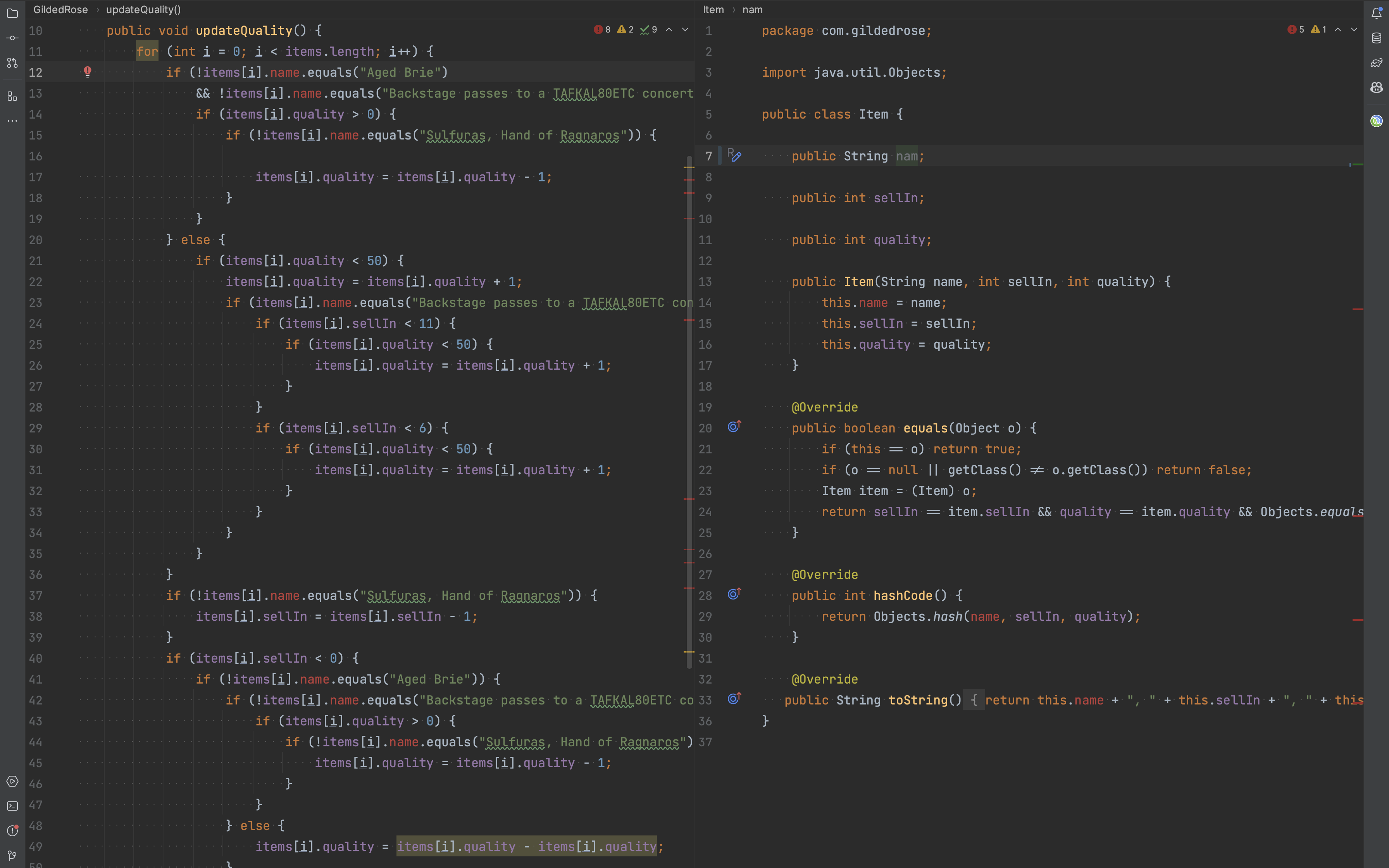
name property from production codeFrom the production code, we figured out possible values for each of these fields in the Item class,
-
name—4 values"Aged Brie""Backstage passes to a TAFKAL80ETC concert""Sulfuras, Hand of Ragnaros""foo"or any otherString
-
sellIn—9 values- 10, 11, 12, 5, 6, 7, -1, 0, 1
-
quality—6 values- -1, 0, 1, 49, 50, 51
Given the complexity and the lack of documentation, we need 4 * 9 * 6 = 216 tests + 1 test (empty array) to gain enough confidence before we make changes to the function. That brings the number of tests required for regression protection to 217.
Hmmm… who has time for that? What do you think?
Enter approval testing
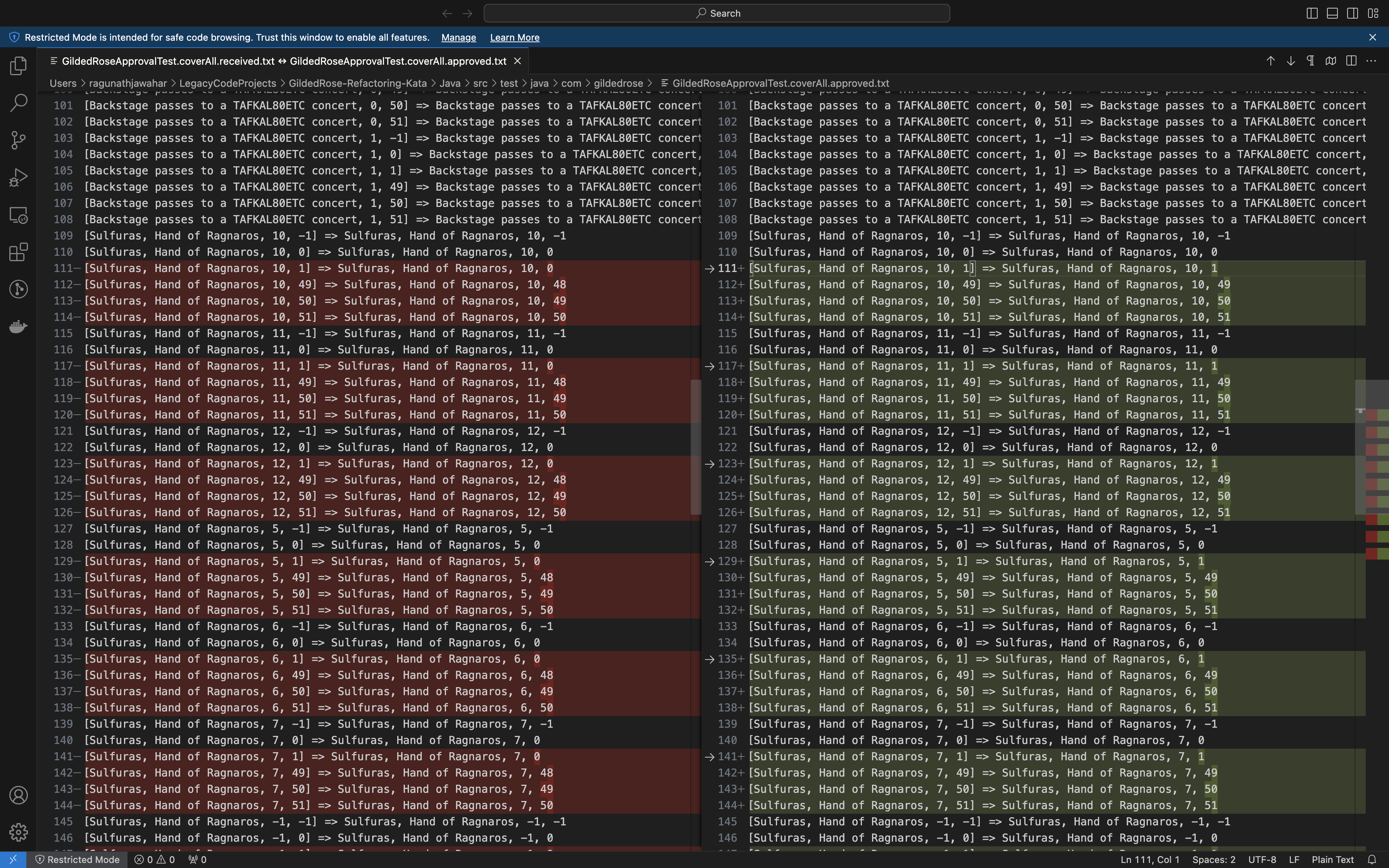
Golden-master testing, snapshot testing, approval testing, call it whatever you want, but they have roots in the same principles. We first capture the system's current behavior and store it in a file as baseline. All future changes to the system are captured and compared against this baseline.
If there are changes, the tool brings up a diff viewer (in the case of textual data). If the differences are undesirable, you discard the changes you made to the system. On the other hand, if the changes are desirable, you review them and update the baseline.
For JVM codebases, we use ApprovalTests.Java. However, different implementations are available for other programming languages.
Combination approval testing
Combination approvals take this up a notch and are helpful in gnarly situations like the Gilded Rose kata (and, of course, in production situations).
Using combination approvals, you can generate these 216 tests (the one test for an empty array is separate). The following code snippet shows you a combination approval test for the Gilded Rose example.
@Test
void coverAll() {
// given
String[] names = {
"Aged Brie",
"Backstage passes to a TAFKAL80ETC concert",
"Sulfuras, Hand of Ragnaros",
"foo"
};
Integer[] sellIns = {
10, 11, 12, 5, 6, 7, -1, 0, 1
};
Integer[] qualities = {
-1, 0, 1, 49, 50, 51
};
// when
Function3<String, Integer, Integer, Item> updateQuality = (name, sellIn, quality) -> {
GildedRose app = new GildedRose(new Item[]{new Item(name, sellIn, quality)});
app.updateQuality();
return app.items[0];
};
// then
CombinationApprovals
.verifyAllCombinations(updateQuality, names, sellIns, qualities);
}
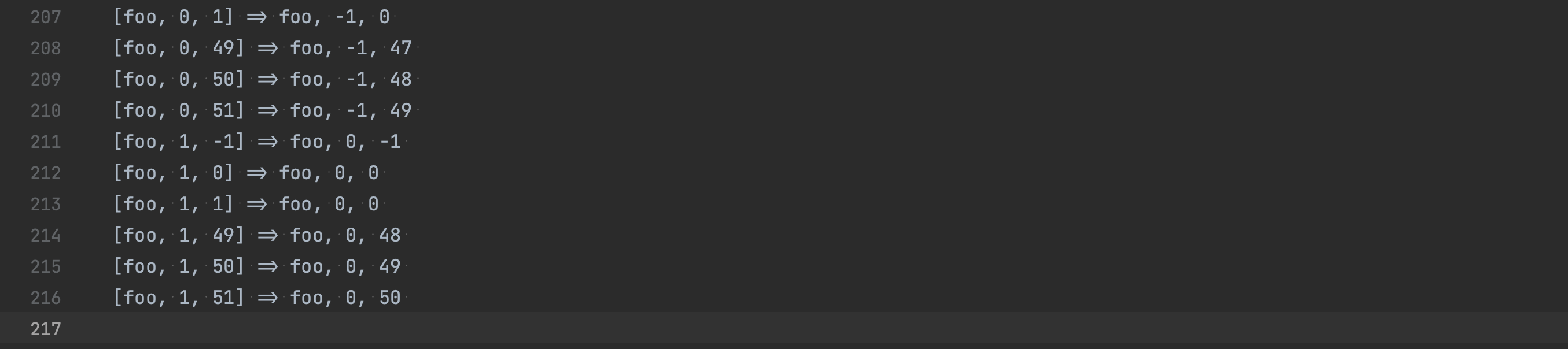
On running the test, approval tests will write the results to a file. Each line in the file stores the input parameters and the corresponding sensed output. You should see 216 lines in the approved file, each representing a single test.
Coverage
With approval testing, achieving 100% code coverage is easy if your input parameters are comprehensive. Since code coverage alone is not a reliable safety indicator, you can validate if you have the correct tests by running mutation tests.
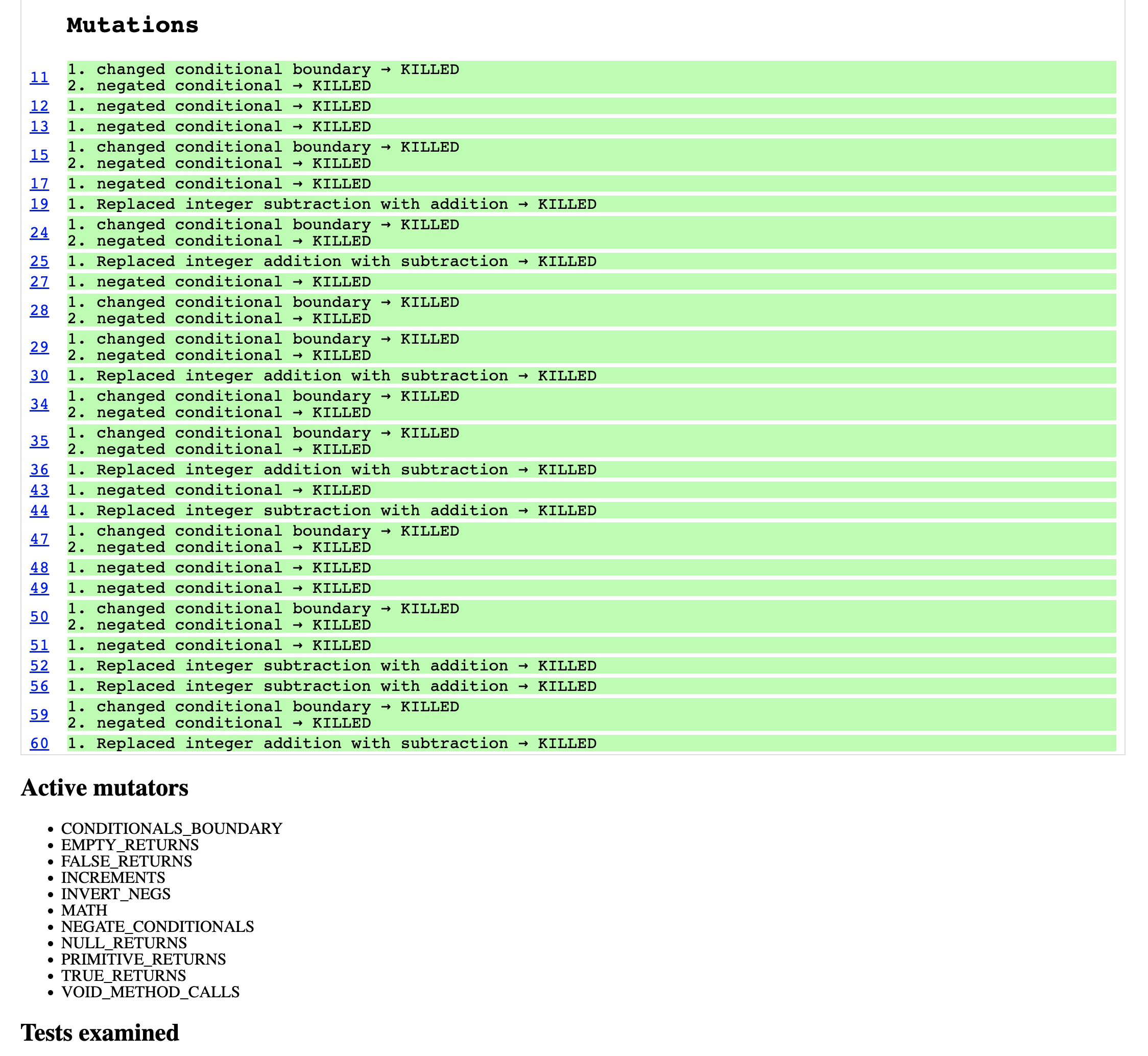
Conclusion
Essentially, if our only tool is a hammer, we see every problem as a nail. Tests, in a traditional sense, may not take you far while dealing with legacy code. But, by varying the tools and techniques, we can work with seemingly impossible coding tasks. But first, we must build a repertoire of these ideas and sometimes come up with our own. Legacy codebases impose many constraints and restrictions, enabling a playground for fostering creativity.
Just because something enables us doesn't mean it doesn't have tradeoffs. The example in this blog post trades off documenting the system's behavior for regression protection. Eventually, after you bring the system to a better state, we could write traditional unit tests to serve us duly as documentation and regression protection. At that point, you can delete the approval test.
Did you find this post helpful? Consider subscribing to stay updated with ideas, tools, and techniques to make your life easier while dealing with large and complex codebases.