Eureka: A pragmatic tool to understand large Java and Kotlin classes
1. Introduction
If you are reading this article, you are not a stranger to the problems caused by large classes in your codebases. They can be challenging to understand and maintain. They may be riddled with poor-quality code because what's one more broken window when the entire class has many of them? It accrues technical debt because large classes often keep growing unless someone cares to do something about it. The longer no one cares, the larger it keeps growing. It may use outdated patterns and technologies, which could make it unappealing for maintainers. Large classes are often old, have maintainers who no longer work with the organization, and may lack documentation and tests.
Nevertheless, if there is an ongoing activity in the class, it's a sign that they are beloved and definitely valuable to your product owners and customers. But a constant nightmare for its maintainers. I wouldn't be surprised if they contribute significantly to your organization's revenue.
Beyond a point, there's a slowdown in everything, and almost every stakeholder can feel it, from adding or removing features to bug fixes and manual or end-to-end automated testing. It becomes so painful that even your non-technical stakeholders are considering a do-over—a rewrite. It might sound like an exciting project if you have never done a rewrite, but if you have a few gray hairs, the r-word might make you nervous.
2. Problems with understanding large classes
To rewrite or refactor is a subject on its own and is ripe for discussion. However, regardless of your chosen path, you still need to understand what's going on.
If we start with the question, "Why are large classes difficult to understand?" here are some of my reasons.
2.1 Too much information
The volume of information is humongous, and as humans, our cognitive abilities only allow us to hold 7 ± 2 objects in our short-term memory. See, The magical number seven, plus or minus two.
2.2 Textual representation of source code
The source code is text. While I have nothing against source code or its textual representation in general, it may not be an optimal representation while trying to understand a large class. Text works best when there is linearity and order. Reading articles and books from top to bottom makes sense, but that kind of reading won't often yield the best result when reading source code.
Source code is a human-friendly way to represent a graph consisting of members (fields, properties, variables, etc.) and relationships between (reads, writes, invokes, etc.) them. If members and relationships are the keys, why get lost in the implementation details when dealing with a large volume of information?
2.3 Hidden problem domain
While reading source code, we tend to miss the forest for the trees. A class's vocabulary can shed some light on the problem domain it is solving. However, looking at the source code as text, it is almost impossible to identify the vocabulary and their frequencies because of the language's syntax and grammar. If we filter out this information, we can focus solely on the problem domain and accelerate our understanding.
2.4 Too many cooks
Large classes may sometimes result from too many folks adding little things to get their job done. Since code can be very personal, you will see a variety of patterns that you may be unfamiliar with. These varied patterns could throw developers off when reading source code to understand the overall picture of the class.
3. Why Eureka?
As a consultant, I get exposed to many different codebases. More often than not, clients expect me to work on the less flattering but incredibly valuable portions of their codebase. And large classes are often a critical problem that I encounter. To deliver on my clients' expectations, I needed a way to accelerate my understanding of these legacy classes. Eureka results from two years of largely failed experiments—some sane and others mostly crazy.
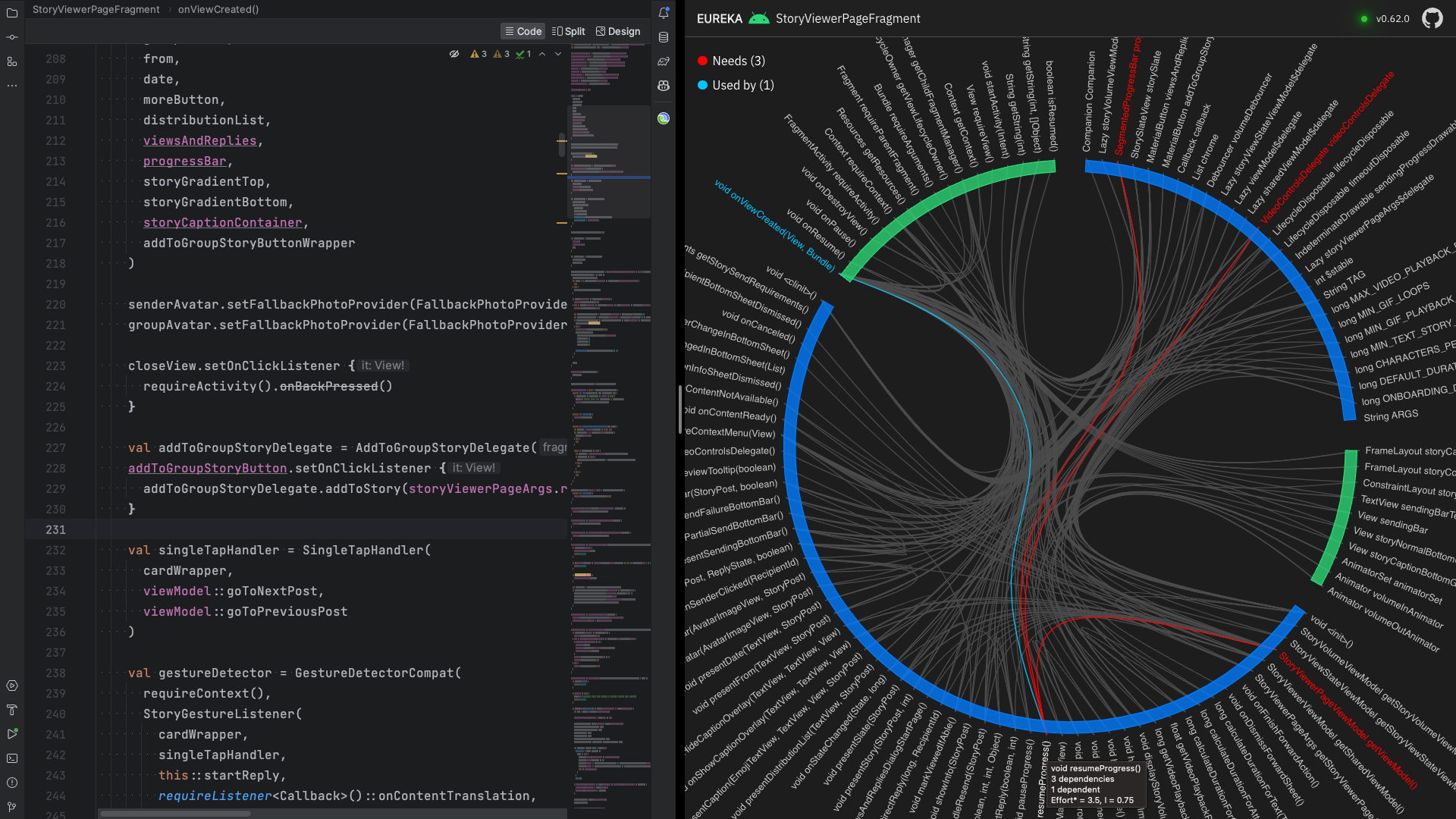
The tool does the following to make it easier to work with large classes.
- It builds a domain vocabulary from types and identifier names of fields and methods. It also counts the frequency of this vocabulary so you know the significance of the concepts within the class.
- It focuses on fields, methods, and the relationships between them. By doing this, it limits the amount of information that developers need to get a bigger picture.
- It uses visualization instead of just using text. Visualization is a powerful idea because we can't fit a 3,000-lines-long class on a single screen, but Eureka can visualize the class on a single screen without a scrollbar.
- The visualization is interactive so that you can focus on the necessary information.
- It updates the graph in real-time for every compilation; therefore, you can see how your class evolves as you edit the source code.
4. Use cases
Eureka can come in handy when trying to understand classes in general, but you can get the most out of it from larger classes. Here are some of the situations where I use it.
- To understand classes in general by looking at the vocabulary and relationships between members.
- It comes in handy when breaking dependencies to get a function under test.
- It can help you discover cohesive units (methods and fields) within a larger class. This network can help you decompose and extract the subgraph as a separate class.
- Evaluate and assess the design of a class by looking at the graph and connected elements.
There could be other use cases for the tool, it is still early, and I can't wait to see how you use it in your development and maintenance workflow.
5. Final notes
- It is not a replacement for reading source code. Reading source code is an essential and valuable skill. Eureka helps developers take a birdseye view of the classes they are interested in.
- The tool can theoretically work with all compiled JVM languages, but currently, it only supports Java and Kotlin. This limitation is because the compiled bytecode can have synthetic functions filtered from the final graph. Now, I don't know an intelligent way to accomplish this result and rely on a less sophisticated way of using regular expressions. Compilers for different languages can produce synthetic functions with various patterns, so I avoid stating that it supports all JVM languages.
- It's pretty early, so please expect bugs. You can file bugs or raise PRs against the repository. Also, I have only tested it on MacOS. However, a friend was able to run it on Windows.
6. Where can I get it from?
Installing it is easy if you already have Homebrew on your machine.
brew install legacycodehq/tap/eureka
For more information and instructions on how to use it, visit the Eureka GitHub repository.
7. Conclusion
Working with large legacy classes can be intimidating, but it doesn't have to be. You may have to find creative ways, use different tools, involve more people, and build new skills to deal with them because it is a different problem than building new software. Do you deal with large legacy classes at work regularly? How do you approach and deal with them? Let me know in the comments.